
【作者】毛灵栋a,郑哲a,孟祥凤b,周育丞a,赵鹏举a,杨芷涵a,龙瀛b*
a 清华大学土木工程系
b 清华大学建筑学院,清华大学恒隆房地产研究中心,清华大学生态规划与绿色建筑教育部重点实验室
【通讯作者邮箱】ylong@tsinghua.edu.cn
【原文信息】Mao, L., Zheng, Z., Meng, X., Zhou, Y., Zhao, P., Yang, Z., & Long, Y. (2022). Large-scale automatic identification of urban vacant land using semantic segmentation of high-resolution remote sensing images. Landscape and Urban Planning, 222, 104384.
https://doi.org/10.1016/j.landurbplan.2022.104384
内容导读
城市空地是世界范围内日益严重的问题。我国城市化进程中也出现了城市收缩、建设用地无序扩张、土地供需错配等现象,这导致出现了许多城市空地。这一方面是土地资源的浪费,另一方面也是城市发展的机遇,需要对空地进行集成管理。然而目前城市空地相关数据较少,传统的人工统计空地的方法耗时耗力,又难以及时更新数据,有必要对城市空地的大规模自动识别方法进行研究。
在已有研究中,不少学者基于高分辨率遥感影像人工识别方法开展对城市空地的研究,但这类研究通常都集中在小规模的单个城市区域,很少有关注大规模的国家地区,这是由于人工识别方法存在高成本和高变异性两大局限性。目前也有少数城市空地自动识别方法的研究,但效果有待提升。近年来,深度学习在图像视觉领域快速发展,出现了不少成熟的图像语义分割网络。这也是城市空地大规模自动识别的潜在机遇,如何将深度学习技术应用于城市空地的大规模自动识别,值得进行探索。
我们提出了一个基于高分辨率遥感影像语义分割的城市空地大规模自动识别框架,并选择中国36个主要城市作为研究区域。该框架利用深度学习技术实现了自动识别,并引入了城市分层的方法来解决跨区域大规模空地识别标准不一致的问题。结果表明,该框架具有良好的识别精度和效率,并具有很强的鲁棒性,为不同的国家和地区的城市空地自动识别提供了可行的途径。
数据与方法
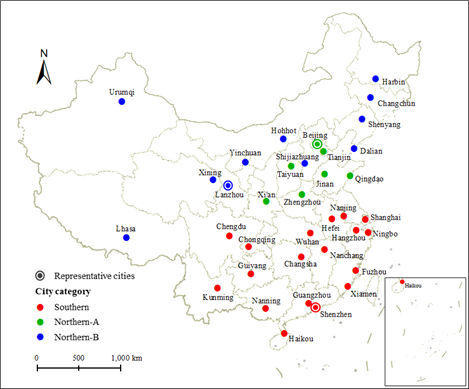
图1 中国36个主要城市的位置、分类,以及各类的代表城市
本文选取了中国36个主要城市为研究对象(图1)。各城市的高分辨率遥感影像数据来自BIGEMAP平台,拍摄时间主要为2019年夏季和秋季,空间分辨率为0.3m左右。城市范围的界定采用城市建成区域而非行政区域,城市边界数据来自北京城市实验室。
城市空地大规模自动识别框架见图2,分为四部分:城市分层、数据标注、模型训练、预测与后处理。
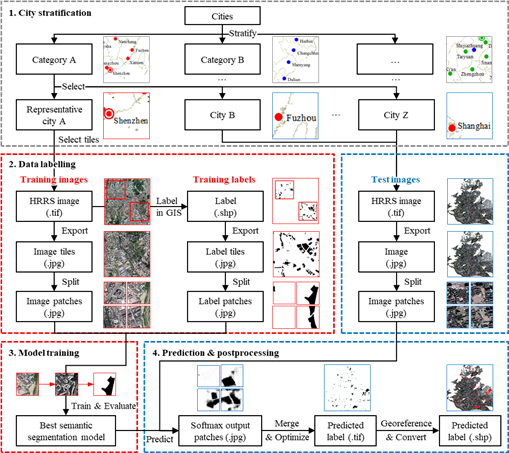
图2 城市空地大规模自动识别框架
首先,确定城市分层策略。由于各城市间的遥感影像及空地特征存在差异,为了使最终迁移预测效果理想,我们以中国四大地理分区为分类基础,进一步归纳各城市空地及非空地特征,包括绿膜、林地、杂草-裸地等等(见图3),将36个城市分为南方、北A、北B三类(见图1),制定了各类城市的具体的空地识别标准,并分别选取了深圳、北京、兰州作为各类的代表城市。每个代表城市训练一个模型,用于该类城市的空地识别。
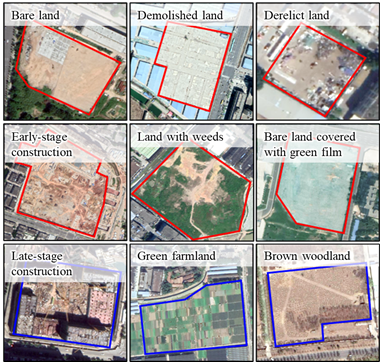
图3 部分特征相似的空地和非空地类型展示(红色为空地,蓝色为非空地)
其次,根据相应的空地识别标准,分别对三个代表城市在ArcGIS软件中进行空地数据标注。取若干地块,按一定的空间分辨率导出遥感影像与空地标注的数据集,一部分用于各个城市的模型训练,另一部分用于后续结果测试,见图4。地块选取原则如下:(1)尽可能包含多类空地和非空地,提高模型鲁棒性;(2)空地率尽可能高,降低数据不平衡导致的模型偏见;(3)地块数量充足,防止训练样本不够导致的过拟合问题。需将导出的训练集和测试集分别进一步分割成边长为256和224像素的小块,再用于模型的训练和测试。
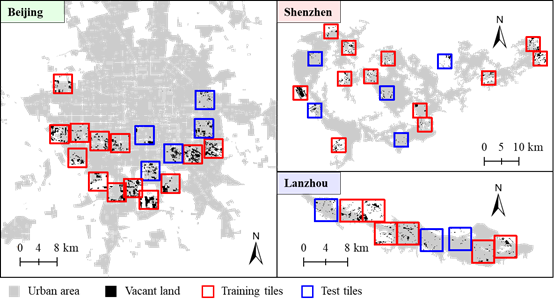
图4 三个代表城市的空地标注范围及数据
模型方面,我们对常用的语义分割模型进行了尝试,发现DeepLabv3效果较好。该模型的核心架构主要有两块:先用ResNet网络骨架进行图像的特征提取,再用ASPP(空洞卷积的空间金字塔池化)获取语义分割结果。模型评价主要指标采用了F2-score,该指标倾向于识别出更多的真实空地。对三个城市分别进行模型训练,根据验证集F2-score选取得到三个最佳模型。
为了最终得到高质量的矢量格式的空地识别结果,提出了两种预测及后处理优化方法。一是混合预测方法,原理是对单一模型预测效果较差的非典型城市(如成都),采用多个模型预测结果取加权平均,以提升预测效果。二是边界优化方法,通过输出模型softmax得分图,依次进行平滑模糊和取阈值截断的操作,以得到较为光滑的空地边界,同时减少识别噪点,利于结果矢量化,见图5。将所有的模型输出小块合并成整体,在ArcGIS中进行重定位和矢量化,得到最终结果。
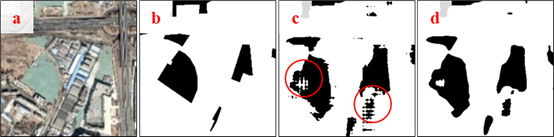
图5 边界优化前后效果比较。a为影像,b为真值,c为优化前结果,d为优化后结果
研究结果
研究结果分为三部分:框架性能评估,空地结果分析,框架鲁棒性测试。
首先,对框架的性能进行评价。在一系列框架参数优化后,我们得到三类城市的最佳模型。南方、北A、北B的模型最佳验证集F2-score分别为0.852、0.888和0.817,较为理想。参数优化主要对数据空间分辨率、模型骨架、模型训练技巧等方面的影响进行了比较分析,具体内容不进行详述,感兴趣的可以参见论文附录。
为进一步评价框架的综合性能,我们将自动识别框架的精度和效率与人工识别方法进行比较。精度方面,我们选取了5块测试地块,将单人识别结果和框架识别结果分别与由5位专业审计人员共同确定的标准结果进行精度比较,计算IoU(intersection over union)。其中人工识别的IoU均值为69.0%,框架识别均值为63.8%,达到了前者的90%,表明自动识别框架的精度与专业审计人员水平接近。同时,人工识别的IoU标准差为16.9%,框架识别标准差为5.1%,说明后者比前者结果更为稳定。效率方面,本次案例中,平均每识别100 km2 范围的城市空地,人工方法需要花费9小时,而采用自动识别框架(包括数据标注、模型训练及预测)仅需花费0.6小时,识别效率极大提升。
其次,我们对36个城市的空地识别结果进行了初步整理分析,部分城市结果展示见图6。基于空地识别结果,计算各城市空地率。其中,36个城市的平均空地率为4.9%,且除南昌外其余城市空地率都低于10%,整体上城市收缩现象不明显。各城市的空地空间分布模式可归纳为:(1)在城市内均匀散布,如长沙和哈尔滨;(2)由城市中心向外围密度逐渐增加,如北京和成都;(3)集中于城市内几个区域,如济南。
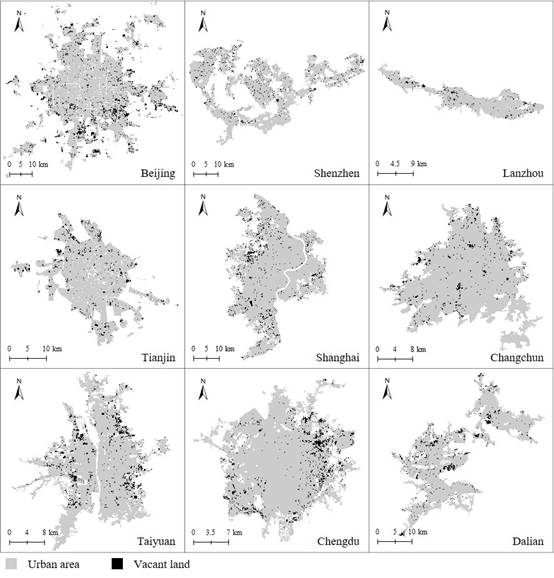
图6 部分城市的空地识别结果展示
最后,进行框架鲁棒性测试,这对于框架的大规模识别适用性至关重要。分别进行了自预测、类间交叉预测、类内预测、混合预测实验(见图7-9)。自预测实验结果显示,三个模型都能较好预测自身代表城市空地。类间交叉预测实验结果显示,三个模型跨类别预测效果欠理想,证明三类城市间空地识别标准存在显著差异,有必要进行城市分层。类内预测实验结果显示,三个模型类内预测效果均较为理想,体现了城市分层方法有效,且模型具有较强的泛化能力。混合预测实验结果显示,对于单一模型预测效果欠理想的城市,采用混合预测方法可以有效改善预测结果。
此外,我们进行了一个消融实验,用三个代表城市的所有训练数据共同训练了一个混合模型(最佳验证集F2-score为0.850),直接用于所有城市的预测。将结果与基于城市分层的预测结果比较(见图7-9),发现混合模型也具有较好的鲁棒性,但在识别精度上还是比采用了城市分层的框架略低,且噪点更多。这再次证明城市分层方法对于多个城市的大规模识别非常重要。
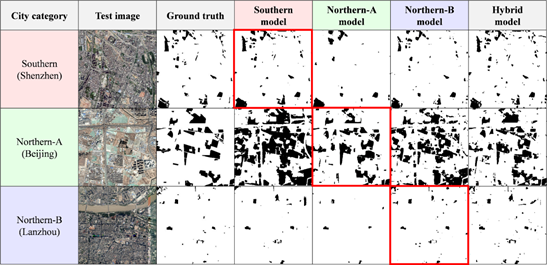
图7 自预测(红框)和类间交叉预测实验结果

图8 类内预测实验结果
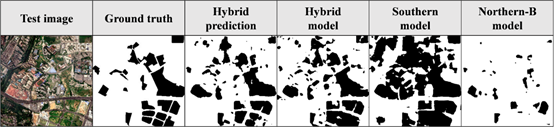
图9 混合预测实验结果
结论与展望
本研究提出了一种基于高分辨率遥感影像语义分割和城市分层的城市空地大规模自动识别框架,并将该框架应用于中国36个主要城市的案例研究,获得了准确高效的空地识别结果。与传统的人工识别方法相比,大规模自动识别框架大大降低了人工成本,效率可提高约15倍;结果具有高度的稳定性;且识别精度可以达到专业审计人员水平的90%。框架采用城市分层和混合预测,具有很强的鲁棒性,在本案例中各个城市中表现良好,为各个国家和地区的城市空地大规模自动识别提供了有力的实践方法。
后续研究可以进一步解决以下问题,包括城市分层自动化、训练数据质量自动化筛查、采用更多波段的高分辨率遥感影像等。